이번 글에서는 시뮬레이션 데이터와 실제 데이터에서 모형의 성능이 어떻게 되는지를 확인해보려고 한다.
Simulations
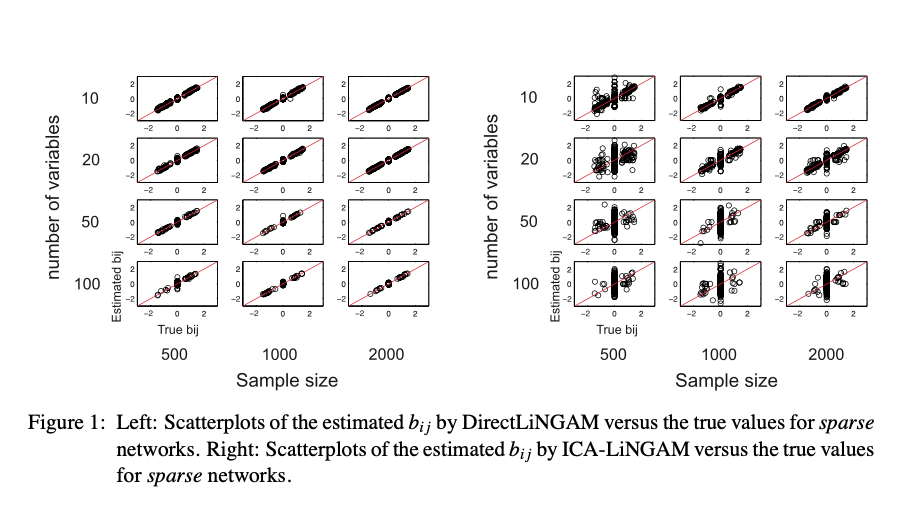
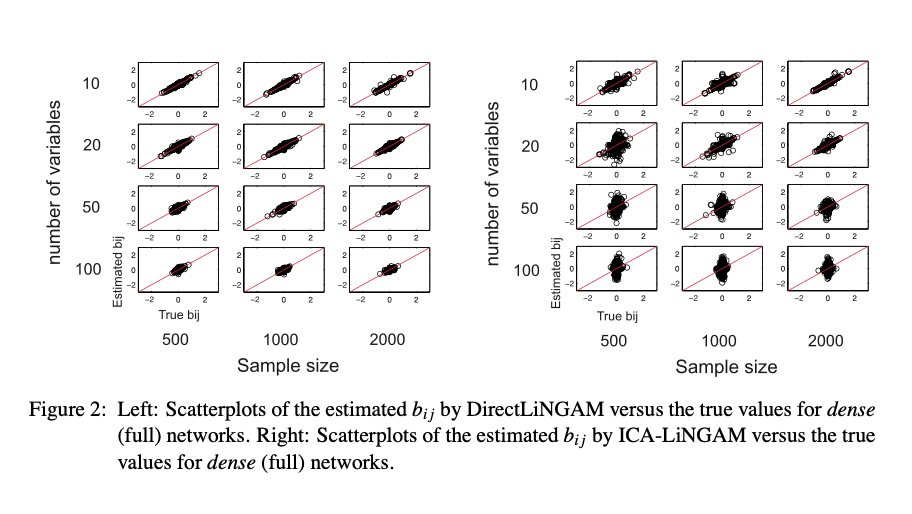
Figure 1은 $\mathbf{B}$가 sparse한 경우, Figure 2는 $\mathbf{B}$가 dense한 경우 DirectLiNGAM(좌)와 ICA-LiNGAM(우)의 성능을 보여주고 있다. x축이 실제 $b_{ij}$, y축이 측정된 $b_{ij}$를 나타내는데, DirectLiNGAM이 ICA-LiNGAM에 비해 $y=x$ 위에 산점도가 집중되어 있는 것을 보아 성능이 훨씬 우수한 것을 확인할 수 있다. 특히 sparse한 경우에는 압도적이다.
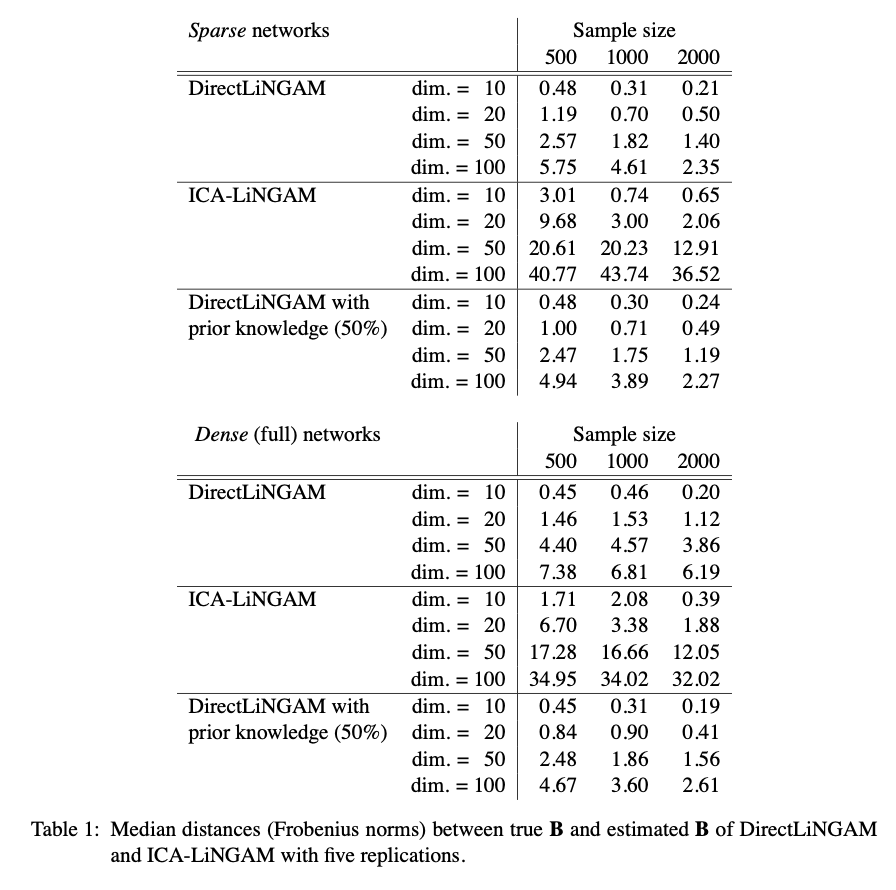
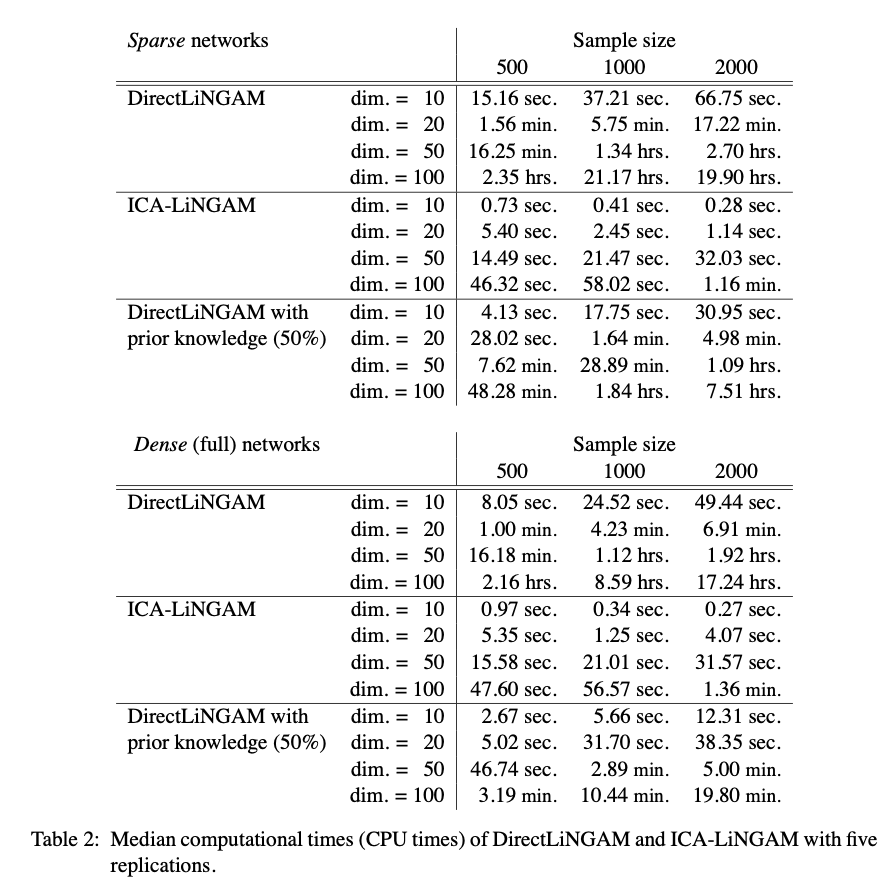
Table 1은 실제 $\mathbf{B}$와 측정된 $\mathbf{B}$ 사이의 Frobenius Norm을 측정하여 그 median 값을 보여주고 있다. Frobenius Norm은 아래와 같이 정의한다.
\[\text{Frobenius Norm}=\sqrt{tr[(\mathbf{B}_{\text{true}}-\widehat{\mathbf{B}})^T(\mathbf{B}_{\text{true}}-\widehat{\mathbf{B}})]}\]Figure 1, Figure 2와 합치하는 결과이다. 전반적으로 DirectLiNGAM이 수치가 적게 나옴으로써 성능이 우수함을 보여주고 있다. 특히 prior knowledge가 있을 경우에는 조금 더 정확한 결과가 나타나는 것을 보여주고 있다.
다만 Table 2를 보면 DirectLiNGAM이 ICA-LiNGAM에 비해 시간이 상당히 오래 걸리는 것을 확인할 수 있다. 논문에 따르면 이는 kernel-based independence measure를 계산하는 과정에서 병목현상이 일어나기 때문이다. 그로 인해 사전정보가 반영된 경우에는 시간이 상당히 많이 줄어드는 것을 확인할 수 있다. 이후 후속연구가 있는지는 모르겠지만, 이 independence measure를 계산하는 알고리즘의 개선이 있다면 더욱 좋은 method가 될 수 있을 것이라고 생각한다.
Applications to Real-world Data
여기서는 실제 데이터와 연결지어 성능을 확인해보고 있다.
Application to Physical Data
논문은 double-pendulum 데이터를 통해 DirectLiNGAM을 학습시켜 보았다. 한국말로는 이중진자라고 하는데, 영상을 보면 얼마나 복잡한 운동인지 알 수 있다.
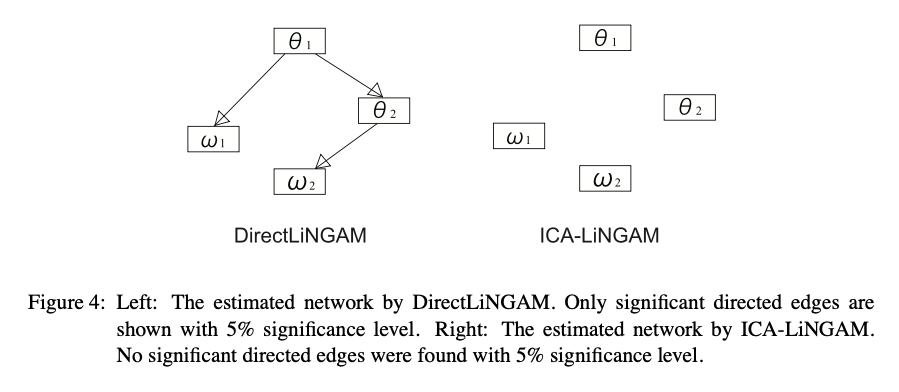
Figure 4를 보면 통계적으로 유의미한 directed edge들만을 남겨놓은 상태로, DirectLiNGAM의 측정한 network와 ICA-LiNGAM의 network를 시각적으로 보여주고 있다. DirectLiNGAM의 network를 보면 $\theta_1$이 $w_1$과 $\theta_2$에, 그리고 $\theta_2$가 $w_2$에 영향을 주는 것을 확인할 수 있다. $\theta_i$와 $w_i$는 각각 $i$번째 진자의 각도와 각속력을 나타낸다. 사실 이중진자 운동에서의 $\theta_1,\theta_2,w_1,w_2$의 관계는 비선형이라고 한다. 그렇기 때문에 우리가 지금 공부하고 있는 모형이 적절하다고 보기 힘들 수도 있겠지만, 이렇게 linear한 모형에서도 꽤 해석 가능하고 흥미로운 결과가 나타났다는 점에서 의미가 있다고 저자는 말하고 있다.
Application to Sociology Data
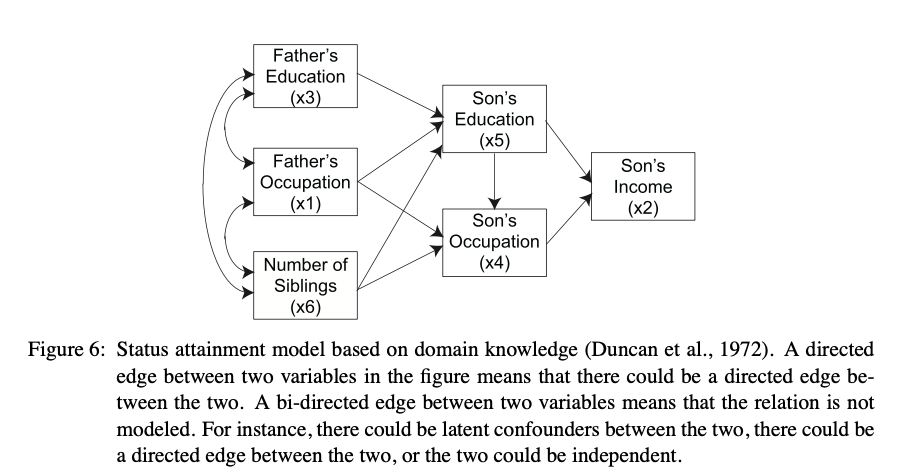
여기서는 사회학적인 데이터를 모형에 적용해보고 있다. General Social Survey 에서는 다양한 사회학적인 데이터를 수집하고 있는데, 논문에서는 총 6가지의 데이터를 수집했다.
\[\begin{aligned} & x_1: \text{father's occupation level} \\ & x_2: \text{son's income} \\ & x_3: \text{father's education} \\ & x_4: \text{son's occupation level} \\ & x_5: \text{son's education} \\ & x_6: \text{number of siblings} \\ \end{aligned}\]논문에서는 domain knowledge에 비추어 보았을 때 아래와 같은 결과를 예상했다.
여기서는 DirectLiNGAM과 ICA-LiNGAM을 학습시킨 것에 더하여 Adaptive Lasso를 통해 pruning을 진행하고 있다. Adaptive Lasso에 대한 간략한 설명은 맨 아래 Appendix에 있다.
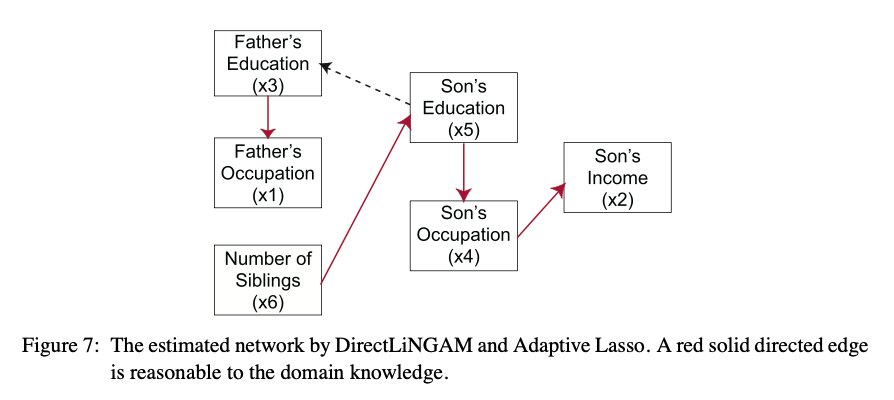
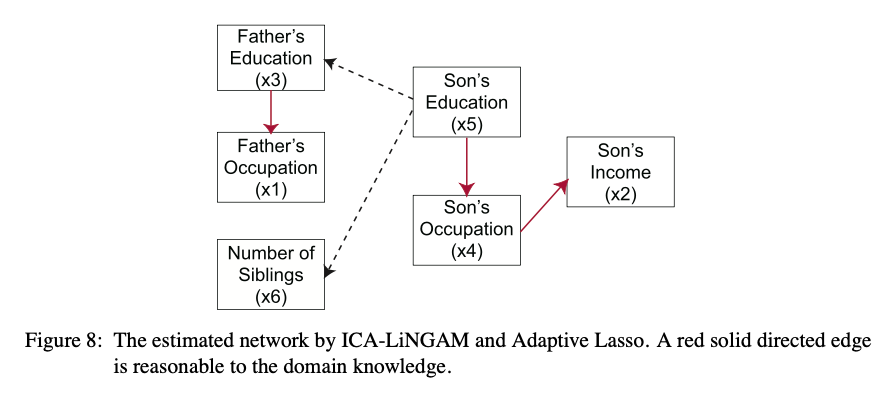
두 그림을 비교해보면 DirectLiNGAM이 훨씬 더 설득력 있는 network를 보여주고 있다.
Conclusion
저자는 i) 독립성 검정을 비롯하여 모형의 assumption을 만족하고 있는지 검정할 수 있는 통계적 방법론, ii) 복잡도를 줄일 수 있는 효율적인 알고리즘의 구현, iii) nonlinear relation 등 DirectLiNGAM 알고리즘의 범위 확장, iv) 다양한 데이터셋을 통한 알고리즘 간 비교검증을 후속연구로 남겨두고 있다.
Appendix A. Adaptive Lasso
Adaptive Lasso는 아래와 같은 손실함수를 최소화하는 $b_{ij}$를 찾는 것이다.
\[\left\|x_i-\sum_{k(j)<k(i)}{b_{ij}x_j} \right\|^2+\lambda\sum_{k(j)<k(i)}\frac{\lvert b_{ij} \rvert}{\lvert \hat{b}_{ij} \rvert^\gamma}\]여기서 $\hat{b}_{ij}$는 OLS를 통해 추정한 $b_{ij}$값으로 넣을 것을 권장하고 있고, $\lambda$와 $\gamma$는 tuning parameter이다. $\lambda$를 크게 할수록, $\gamma$를 작게 할수록 $b_{ij}$의 크기에 대한 penalty가 커져 필요없는 edge들이 0으로 사라지게 될 것이다.
여기까지 DirectLiNGAM 논문을 살펴보았다. 알고리즘을 보면 복잡도는 커졌지만 로직 자체는 훨씬 더 간단해졌다. 덕분에 빠른 속도로 논문을 소화할 수 있었던 것 같다. 다만 저자가 후속연구로 언급했던 것처럼 아직 통계적 검정이 논의되지 않았다는 점이 논문의 아쉬운 점이 될 것 같다.