이번에는 논문에서 제안한 모형이 실제로 얼마나 정확하게 예측을 하는지를 확인해보려고 한다.
Simulations
Estimation of $\mathbf{B}$
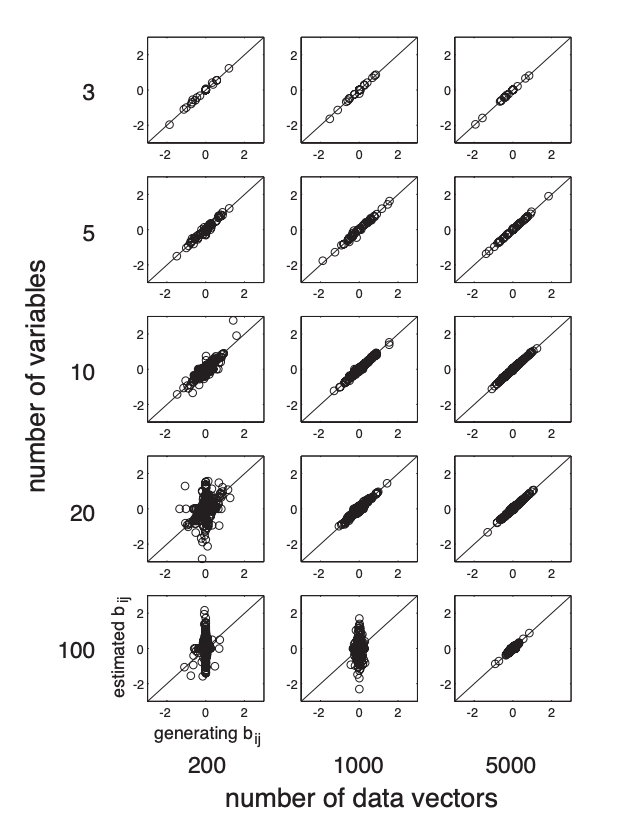
논문에 첨부되어 있는 figure이다. 전반적으로 높은 정확도를 보여주고 있다. 다만 $\mathbf{B}$의 차원이 $100 \times 100$일 경우에는 적은 데이터로 높은 정확성을 확보하기는 힘들지만 이 역시 데이터 수가 많으면 많아질수록 정확도가 올라가는 것을 확인할 수 있다.
Pruning Edges
이 논문에서 중요한 것 중 하나가 바로 가지치기인데, 이 부분에 대한 성능 역시 표로 정리되어 있다. $10 \times 10$일 경우만 여기에서 확인해보자.
$n=10000$
| Actual:True | Actual:False | |
|---|---|---|
| Predict:True | 32,477(94.1%) | 1,011(9.6%) |
| Predict:False | 2,046(5.9%) | 9,466(90.4%) |
- True Positive (1,1): the numbers of correctly identified edges
- True Negative (2,2): the numbers of correctly identified absence of edges
- False Positive (1,2): the number of edges falsely added
- False Negative (2,1): the number of edges falsely missing
전반적으로 성능이 아주 좋은 것을 확인할 수 있다.
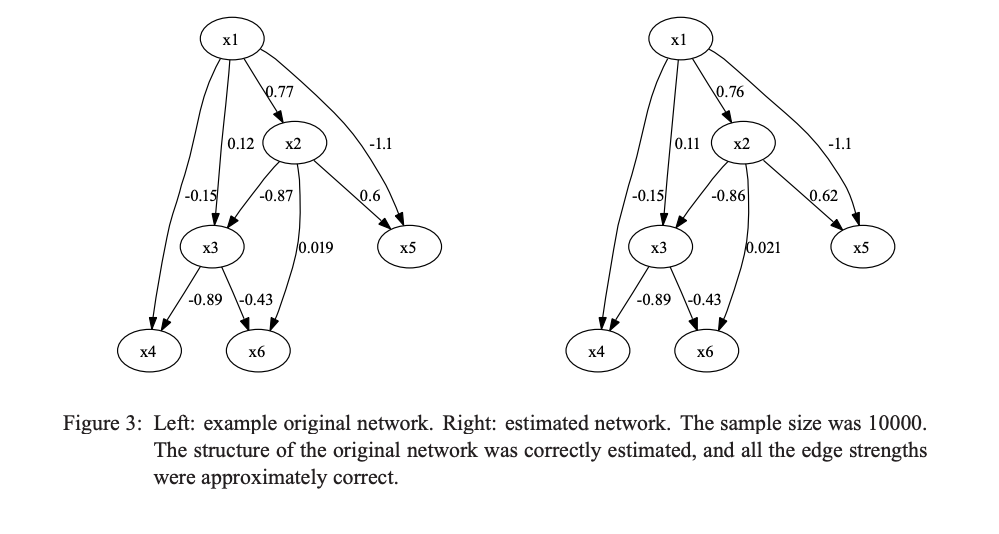
위 그림에서는 실제 network(좌)와 예측된 network(우)가 비교되고 있다. 구조는 정확하게 추정되었고, 계수들은 조금씩 차이가 나지만 무시할 수 있을만큼 정확하게 추정되었다.
Examples With Real-World Data
논문에서는 실제 데이터로 $\text{AR}(p)$ 모형의 시계열을 활용하고 있다. $\text{AR}(p)$ 모형은 다음과 같은 형태의 시계열 모형을 말한다.
\[X_t = \phi_1X_{t-1}+\phi_2X_{t-2}+\dots+\phi_pX_{t-p}+\epsilon_t \quad \epsilon_t \sim WN(0,\sigma^2)\]만약 LiNGAM approach를 적용하고 싶다면 여기서 $\epsilon_t$는 $i.i.d.$하게 non-Gaussian 분포를 따라야 할 것이다.
논문에서는 시계열 데이터를 $p$의 time window로 쪼개 데이터셋을 만들었다. 즉, $X_1,X_2,\dots,X_{3p+3}$의 시계열자료가 있다면 $X_1,\dots,X_{p+1}$, $X_{p+2},\dots,X_{2p+2}$, $X_{2p+3},\dots,X_{3p+3}$로 총 세개의 데이터를 확보하는 것이다. 하지만 이렇게 생각할 경우 뒤의 두 개 데이터셋에서는 confounding 문제가 있을 수 있다는 점을 논문에서 언급하고 있다.
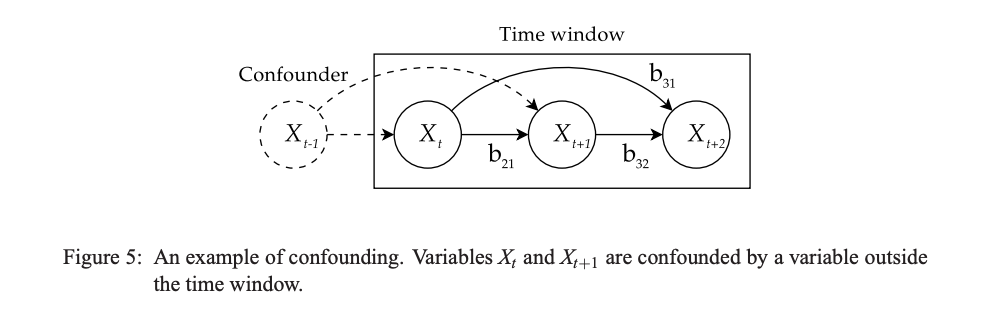
$\text{AR}(2)$ 모형을 생각해보자. 그렇다면 $X_t,X_{t+1},X_{t+2}$ 데이터에서 $X_t,X_{t+1}$은 모두 $X_{t-1}$의 영향을 받게 되기 때문에 이처러 외부 변수의 영향을 받는 데이터는 LiNGAM 모형 적합에 방해가 되는 것이다. 이 점을 염두에 둘 필요가 있다.
다양한 데이터를 접목해본 결과 다음과 같이 결과들이 분류되는 것을 확인하였다.
- 인과관계가 정확히 추정된 케이스 (5건)
- 인과관계가 역으로 바뀐 채 추정된 케이스 (9건)
- $\mathbf{B}=\mathbf{O}$ 로 추정된 케이스 (1건)
- 인과관계에서의 추정치가 잘 잡히지 않은 케이스 (7건)
2번은 Random Walk 때문에 일어날 수 있는 현상이라고 설명하였다. Random Walk는 다음과 같은 시계열 형태를 말한다.
\[X_t = X_{t-1}+\epsilon_t\]즉, $\text{AR}(1)$ 모형에서 $\phi_1=1$인 형태라고 생각하면 쉬운데, 이 경우에는 stationary 가정을 만족하지 못할뿐만 아니라 인과관계를 파악할 수 없다. 인과관계가 역으로 바꾼 채 추정되어도 우리가 알 길이 없다는 뜻이다.
3번은 변수들끼리 인과적으로 묶이지 않은 케이스임을 의미하는데, 이것은 데이터셋에 문제가 있을 수 있다고 해명하고 있다.
그리고 4번으로는 여러가지 문제상황이 있을 수 있다고 설명하고 있다. process가 실제로 non-linear할 수도 있다는 점, 오차항이 정규분포를 따른다는 점, confounding variable이 있을 수 있다는 점 등 다양한 요인을 제시하고 있다.
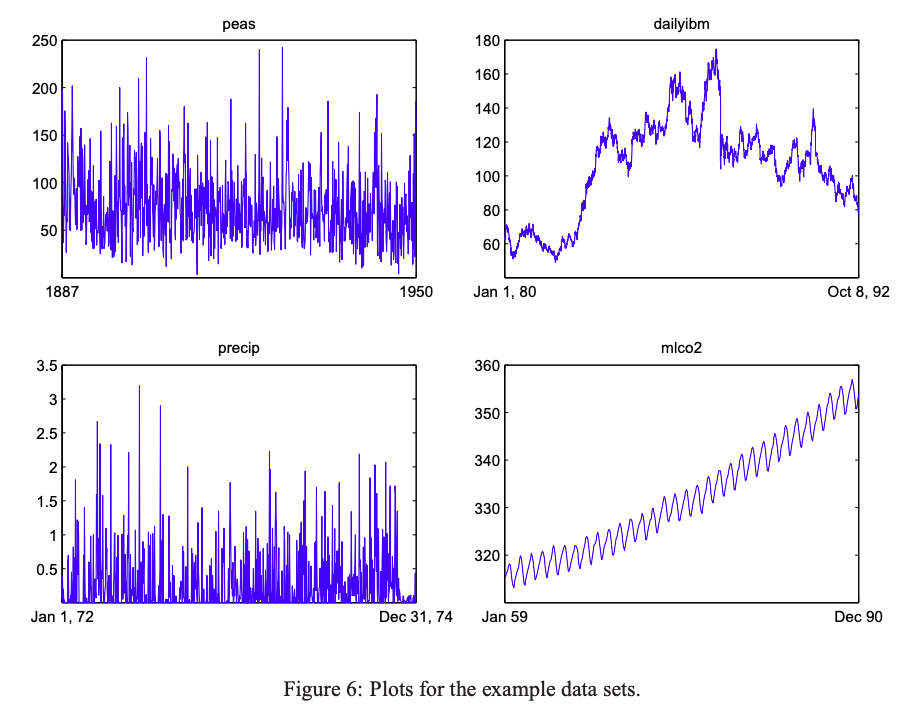
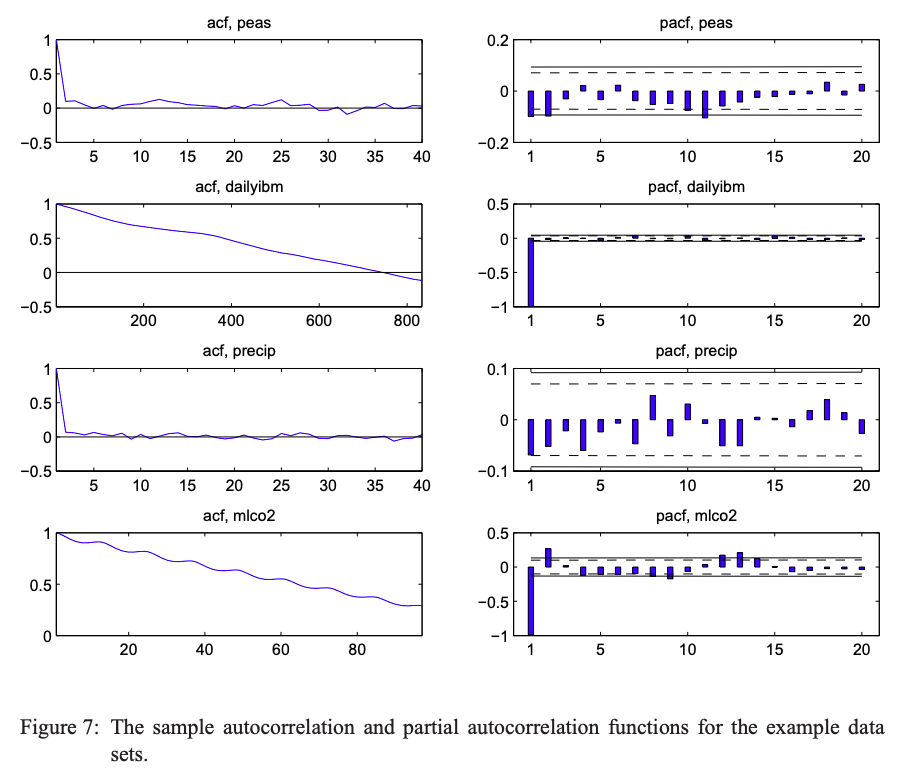
peas 데이터는 1번 케이스로 정확히 잘 추정된 사례에 해당한다. 시계열도를 보아도 정상성이 어느정도 만족되는 것을 확인할 수 있고, SACF와 SPACF도 약간의 주기를 보이는 것 같긴 하지만 $\text{AR}(2)$ 모형의 ACF,PACF와 흡사한 것을 확인할 수 있다.
dailyibm 데이터는 2번 케이스에 해당한다. 보면 SACF와 SPACF가 random walk의 ACF,PACF와 닮았다. 논문도 아마 이 데이터가 random walk이기 때문에 그런 현상이 일어나지 않았을까 추측하고 있다.
precip 데이터는 3번 케이스에 해당한다. SPACF를 보면 전부 -0.1에서 0.1 사이로 유의미하지 않은 것을 확인할 수 있다.
mlco2 데이터는 마지막 4번 케이스에 해당한다. 논문에서는 다양한 가능성을 제시하고 있다. 우선 SACF를 보면 약간의 주기가 있는 것을 확인할 수 있고, non-linear과 confounding variable의 존재 등이 원인일 수 있다고 보고 있다.
이렇게 네 번에 걸쳐 A Linear Non-Gaussian Acyclic Model for Causal Discovery 논문을 리뷰했다. 찾아보니 이에 대한 후속 연구도 정말 많이 진행된 것 같아서 꾸준히 꼬리를 물며 찾아봐야겠다.
Reference
-
이상열. (2013). 시계열 분석 이론 및 SAS 실습(pp.142~191). 자유아카데미.