우선 네이버 뉴스 기사를 긁어오는 코드를 짜봤다. 아무래도 뉴스기사들을 훑어보며 종목이 어떠한 상황에 있는지 파악할 필요가 있겠다는 생각이 들었다. 그리고 뭐 겸사겸사…?
네이버 뉴스 기사 크롤링 관련 코드는 워낙 많기도 하고 레퍼런스도 많지만 사이트 구조가 최근와서 좀 달라진 것 같다. 그래서 그냥 그대로 긁어다가 쓰면 크롤링이 안 되는 경우가 많다. 그래서 직접 짰다,,ㅎㅎ
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup
import datetime as dt
class NaverNews:
"""
This class is for crawling naver news articles.
"""
def __init__(self,search,start_date,end_date,search_area):
"""
Args:
search (str): keyword for searching news articles.
start_date (datetime.datetime): minimum value of date when the article was written.
end_date (datetime.datetime): maximum value of date when the article was written.
search_area (int): the number of pages you want to search.
"""
self.search = search
self.start_date = str(start_date).split(' ')[0].replace('-','.')
self.end_date = str(end_date).split(' ')[0].replace('-','.')
self.search_area = search_area
self.params = {}
self.headers = {'User-Agent': 'Mozilla/5.0'}
self.url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum'
self.result = pd.DataFrame()
def set_params(self):
"""
Set the parameters for query string.
"""
ds_nso = self.start_date.replace('.','')
de_nso = self.end_date.replace('.','')
params = {
'where': 'news',
'query': self.search,
'start': 1,
'ds': self.start_date,
'de': self.end_date,
'nso': f'so:r,p:from{ds_nso}to{de_nso},a:all'
}
self.params = params
return
def crawling(self):
"""
Do crawling.
"""
ar_date = []
ar_url = []
ar_title = []
ar_photo_text = []
ar_content = []
for i in range(self.search_area):
if i == 0:
self.params['start'] = 1
else:
self.params['start'] = i * 10 + 1
raw = requests.get(self.url, headers = self.headers, params = self.params)
html = BeautifulSoup(raw.text, 'html.parser')
articles = html.select('ul.list_news > li')
for ar in articles:
n = len(ar.select('a.info'))
if n != 2: # 네이버뉴스기사는 n == 2
continue
else:
date = ar.select('span.info')[-1].text # 기사 날짜
title = ar.select_one('a.news_tit')['title'] # 제목
articleUrl = ar.select('a.info')[1]['href'] # 네이버 뉴스기사 링크
innerRaw = requests.get(articleUrl, headers = self.headers)
innerHtml = BeautifulSoup(innerRaw.text, 'html.parser')
print(title)
try:
photo_text = innerHtml.select_one('span.end_photo_org').text # 사진 하단 부연설명
content = innerHtml.select_one('#dic_area').text.replace(photo_text, '') # 본문기사
except AttributeError: # 사진 하단 부연설명이 아무것도 없을 경우
try:
photo_text = np.nan
content = innerHtml.select_one('#dic_area').text # 본문기사
except AttributeError:
photo_text = np.nan
content = np.nan
ar_date.append(date)
ar_url.append(articleUrl)
ar_title.append(title)
ar_photo_text.append(photo_text)
ar_content.append(content)
result = pd.DataFrame({
"date" : ar_date,
"url" : ar_url,
"title" : ar_title,
"content" : ar_content,
"sub_text" : ar_photo_text
})
self.result = result
return
def save(self,save_path):
"""
Save the result at save_path.
Args:
save_path (str): Directory where you want to save the result.
"""
self.result.to_csv(save_path,index = False)
우선 한줄한줄 찬찬히 들여다보도록 하자.
__init__
def __init__(self,search,start_date,end_date,search_area):
"""
Args:
search (str): keyword for searching news articles.
start_date (datetime.datetime): minimum value of date when the article was written.
end_date (datetime.datetime): maximum value of date when the article was written.
search_area (int): the number of pages you want to search.
"""
self.search = search
self.start_date = str(start_date).split(' ')[0].replace('-','.')
self.end_date = str(end_date).split(' ')[0].replace('-','.')
self.search_area = search_area
self.params = {}
self.headers = {'User-Agent': 'Mozilla/5.0'}
self.url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum'
self.result = pd.DataFrame()
순서대로 검색단어, 시작일, 종료일, 몇 페이지까지 크롤링 할건지를 받는다.
다른 코드와 연결시키기 위해 시작일과 종료일의 경우 datetime.datetime 형으로 받았는데, 크롤링할 때에는 2022.01.28 형태의 문자열로 넣어주어야 하기 때문에 약간의 전처리를 진행했다.
search_area는 내가 10으로 설정하면, 10페이지까지만 크롤링을 하고 그런 식이다.
set_params
def set_params(self):
"""
Set the parameters for query string.
"""
ds_nso = self.start_date.replace('.','')
de_nso = self.end_date.replace('.','')
params = {
'where': 'news',
'query': self.search,
'start': 1,
'ds': self.start_date,
'de': self.end_date,
'nso': f'so:r,p:from{ds_nso}to{de_nso},a:all'
}
self.params = params
return
Request를 넣어줄 때에는 params라는 딕셔너리에 내가 원하고자 하는 조건을 걸어준 다음 보내야 한다.
쿼리스트링은 크롬에서 개발자도구를 통해 확인할 수 있다.
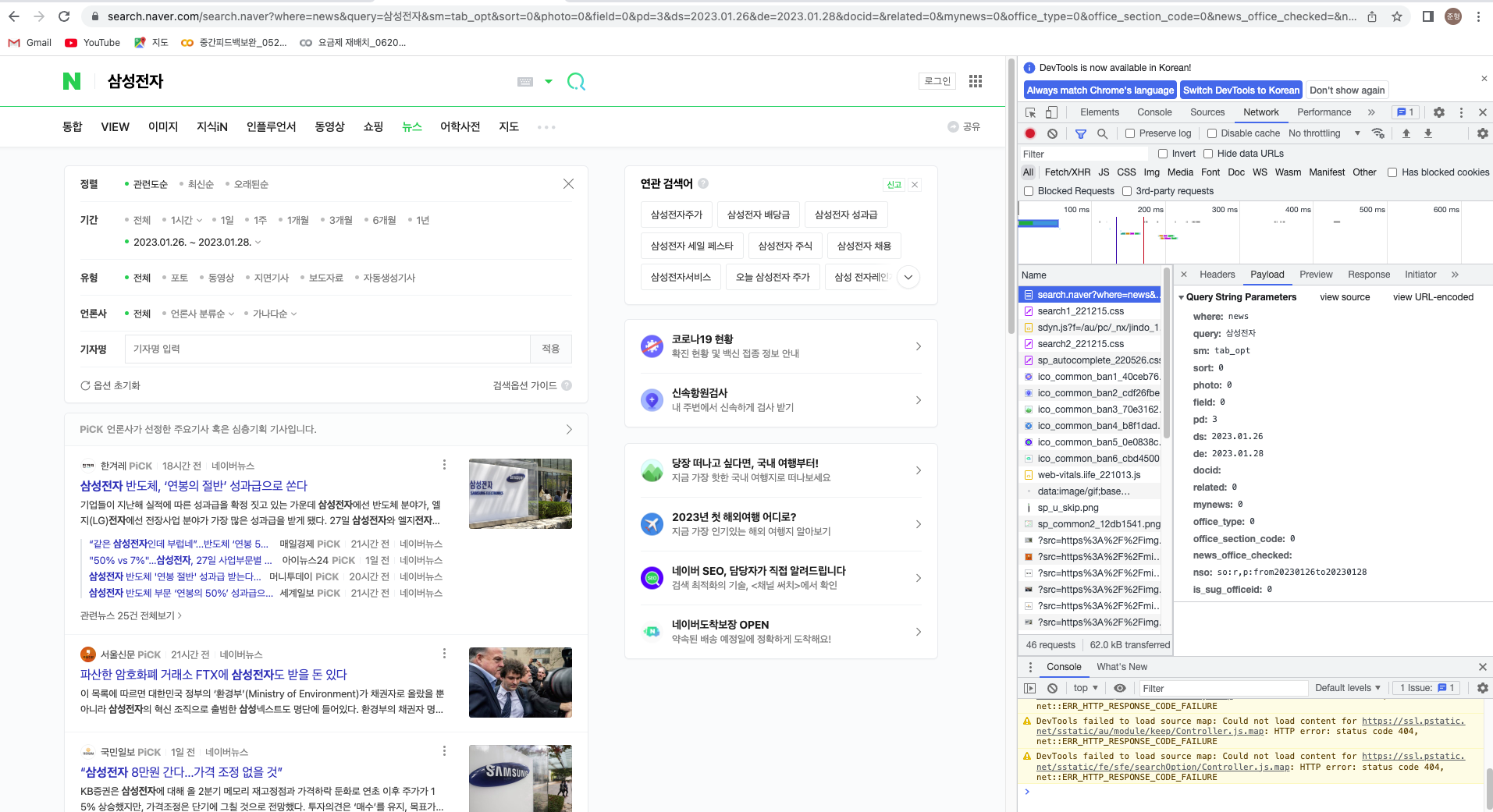
crawling
def crawling(self):
"""
Do crawling.
"""
ar_date = []
ar_url = []
ar_title = []
ar_photo_text = []
ar_content = []
for i in range(self.search_area):
if i == 0:
self.params['start'] = 1
else:
self.params['start'] = i * 10 + 1
raw = requests.get(self.url, headers = self.headers, params = self.params)
html = BeautifulSoup(raw.text, 'html.parser')
articles = html.select('ul.list_news > li')
for ar in articles:
n = len(ar.select('a.info'))
if n != 2: # 네이버뉴스기사는 n == 2
continue
else:
date = ar.select('span.info')[-1].text # 기사 날짜
title = ar.select_one('a.news_tit')['title'] # 제목
articleUrl = ar.select('a.info')[1]['href'] # 네이버 뉴스기사 링크
innerRaw = requests.get(articleUrl, headers = self.headers)
innerHtml = BeautifulSoup(innerRaw.text, 'html.parser')
print(title)
try:
photo_text = innerHtml.select_one('span.end_photo_org').text # 사진 하단 부연설명
content = innerHtml.select_one('#dic_area').text.replace(photo_text, '') # 본문기사
except AttributeError: # 사진 하단 부연설명이 아무것도 없을 경우
try:
photo_text = np.nan
content = innerHtml.select_one('#dic_area').text # 본문기사
except AttributeError:
photo_text = np.nan
content = np.nan
ar_date.append(date)
ar_url.append(articleUrl)
ar_title.append(title)
ar_photo_text.append(photo_text)
ar_content.append(content)
result = pd.DataFrame({
"date" : ar_date,
"url" : ar_url,
"title" : ar_title,
"content" : ar_content,
"sub_text" : ar_photo_text
})
self.result = result
return
크롤링은 함수가 좀 길기 때문에 이 안에서도 조금씩 쪼개서 봐야겠다.
ar_date = []
ar_url = []
ar_title = []
ar_photo_text = []
ar_content = []
기사가 작성된 날짜, url 링크, 기사 제목, 사진 밑에 달린 부연설명, 컨텐츠 순이다. 기사를 하나씩 돌면서 저 리스트에 append를 한 다음 마지막에 다 끝나면 데이터프레임으로 만드는 것이다. 사진 부연설명은 넣을까 말까 하다가 일단 첫단계에서는 데이터가 많을수록 좋을 것 같아 일단 넣었다.
for i in range(self.search_area):
if i == 0:
self.params['start'] = 1
else:
self.params['start'] = i * 10 + 1
raw = requests.get(self.url, headers = self.headers, params = self.params)
html = BeautifulSoup(raw.text, 'html.parser')
articles = html.select('ul.list_news > li')
1페이지부터 search_area 페이지까지 돌면서 크롤링을 하는 식이다. 그 반복문의 시작이 어떻게 되는지를 살펴보자.
우선 네이버 웹페이지는 페이지 쪽수가 쿼리스트링에 특이하게 맵핑되어 있는데, 1페이지는 1, 2페이지는 11, 3페이지는 21, …, 10페이지는 91, 11페이지는 101, … 이런식이다. 그래서 start 키에 넣어줄 때 위의 방식처럼 전처리를 해주어야 한다.
그 다음
articles = html.select('ul.list_news > li')
를 실행하면 articles 변수에 해당 페이지에 있는 기사들이 리스트로 들어간다. 그럼 또 이 articles 에 대해서 반복문을 돌려주어야 이제 기사 단위로 데이터가 수집될 것이다.
for ar in articles:
n = len(ar.select('a.info'))
if n != 2: # 네이버뉴스기사는 n == 2
continue
else:
date = ar.select('span.info')[-1].text # 기사 날짜
title = ar.select_one('a.news_tit')['title'] # 제목
articleUrl = ar.select('a.info')[1]['href'] # 네이버 뉴스기사 링크
innerRaw = requests.get(articleUrl, headers = self.headers)
innerHtml = BeautifulSoup(innerRaw.text, 'html.parser')
print(title)
이제 여기서 또 하나의 조건이 들어가야 하는데, 그냥 아무 뉴스 기사 사이트에서 긁어오는 건 html 구조가 다 다르기 때문에 불가능하다. 그래서 html 구조가 통일되어 있는 네이버뉴스만 가지고 와야 하는데 이 부분에서 그걸 해준다.
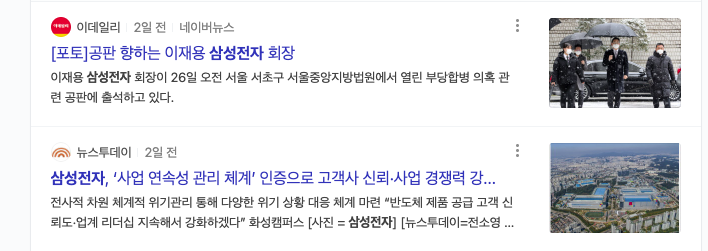
보면 네이버뉴스 링크가 있는 기사가 있고 없는 기사가 있다. 없는 기사의 경우에는 a.info에 네이버뉴스에 대한 정보가 없어 길이가 1인 반면, 있는 기사는 길이가 2이다. 사실 이 부분은 아주 확실하진 않은데 내가 지금까지 봤을 땐 다 그랬다.
그렇게 해서 네이버뉴스가 있는 것이 확인되면 사이트로 들어간다. 이 때 사이트로 들어갈 때 주의해야할 점은 링크를 기사제목에 딸린 링크가 아니라 네이버뉴스에 딸린 링크로 들어가야 한다.
그리고 크롤링이 잘 되는지 확인하기 위해 기사제목을 print하도록 만들었다.
try:
photo_text = innerHtml.select_one('span.end_photo_org').text # 사진 하단 부연설명
content = innerHtml.select_one('#dic_area').text.replace(photo_text, '') # 본문기사
except AttributeError: # 사진 하단 부연설명이 아무것도 없을 경우
try:
photo_text = np.nan
content = innerHtml.select_one('#dic_area').text # 본문기사
except AttributeError:
photo_text = np.nan
content = np.nan
ar_date.append(date)
ar_url.append(articleUrl)
ar_title.append(title)
ar_photo_text.append(photo_text)
ar_content.append(content)
여기서 try except 구문을 넣은 것은 다름 아니라 네이버뉴스에서도 html 구조가 달라 에러가 뜰 때가 있었기 때문이다. 찾아보니 다 옛날기사였다. 옛날기사에서는 html 구조가 지금과는 많이 달라 어쩔 수가 없는 것 같다. 크롤링에 실패할 경우에는 NaN 값을 채워주도록 만들었다.
result = pd.DataFrame({
"date" : ar_date,
"url" : ar_url,
"title" : ar_title,
"content" : ar_content,
"sub_text" : ar_photo_text
})
self.result = result
return
그럼 끝!
Result
cls = NaverNews(
search = "삼성전자",
start_date = datetime.datetime(2018,3,22),
end_date = datetime.datetime(2018,3,23),
search_area = 10
)
cls.set_params()
cls.crawling()
cls.result # 최종 결과 데이터프레임
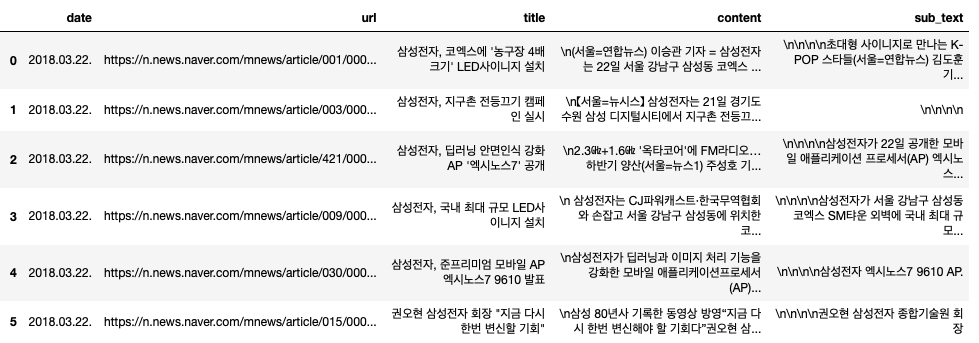
만약 크롤링이 전부 정상적으로 되었다면 위와 같은 데이터프레임이 나오게 되고 self.save() 함수를 통해 csv 파일을 원하는 경로에 저장하면 된다.